
Programming—especially when you are just starting out, learning how to code—endows you with a sense of control, a sense of power. Often, its like playing a God game, at least when you do it recreationally. Of course, you need to spell out to extremely high precision exactly what you want the machine to do. But, then its forced to carry out your instructions. Its forced to obey.
You can derive a similar sense of fun from mathematics. You can force math to do amazing things on your behalf. Of course, you need to figure out the right equations, but once you code them into your programs, the formulae are under your control. They too will obey.
To show you what I mean, lets do some recreational programming. Lets recreate the Amiga Juggler from scratch using core Java.
In the fall of 1986, Eric Graham discovered that the Amiga 1000 personal computer, running at a meager 7.16 MHz, was powerful enough to ray trace simple 3D scenes. His test animation consisted of an abstract, humanoid robot juggling 3 mirrored balls. It stunned the Amiga community including the executives at Commodore, who later acquired the rights to the animation for promotional purposes.
I want to share some of the pain that Eric Graham went through by coding this from first principles. To accomplish this, Ill have to develop a mini ray tracer, a program that generates images by simulating the optical properties of light interacting with an environment. Ill delve into linear algebra, geometry, trigonometry and a bit of calculus. Hopefully, you vaguely remember learning about these topics back in school. Lets review.
A three-dimensional vector is simply a list of 3 numbers. It can represent a point in space, a direction, a velocity, an acceleration, etc. It can even represent a color in RGB color space. For coding simplicity, Ill represent a vector as an array of doubles of length 3. An object with 3 double fields is probably more efficient, but Im trying to minimize the amount of code to write.
Many vector functions act on the individual components independently. For example, to add 2 vectors together, you simply need to add each pair of components together.
// a = b + c
|
The magnitude of a vector (the length of a vector) is computing using the 3-dimensional version of the Pythagorean Theorem.
// |v|
|
You can scale a vector (change its length) by multiplying it by a constant (a.k.a. a scalar).
// a = b * s
|
You can negate a vector by scaling by −1, reversing its direction. If you divide a vector by its magnitude (scale by 1/magnitude), you end up with a unit vector (a vector of length 1).
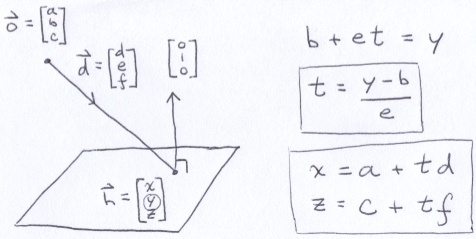
Vectors can do cools things. Consider an astronaut floating in space at some origin point o that fires a gun in direction d (a unit vector). The bullet leaves the gun and it continues to travel indefinitely in a straight line at a constant velocity (a unit of distance for every unit of time). Its position at any time is given by the ray equation.
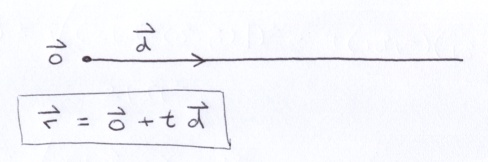
Above, a vector is scaled by a constant and the result is added to another vector.
// a = b + c * s
|
Most vector functions are intuitive, but 2 are mysterious: dot-product and cross-product.
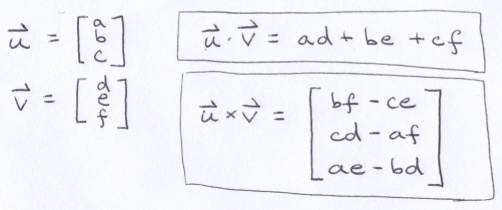
You may recall this trick involving a determinant that is helpful for remembering how to perform cross product:
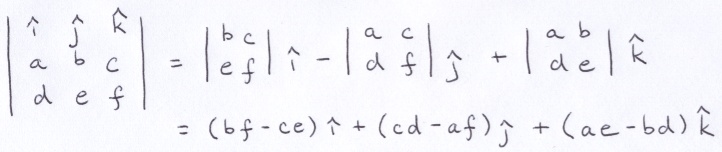
The notation used in the trick actually reveals a little bit about the historic origin of dot product and cross product. They come from a number system invented by William Hamilton in 1843 called quaternions. Hamilton attempted to extend complex numbers by introducing a new imaginary-like constant j, but he could not work out a self-consistent system. According to legend, while out on a walk in Dublin by the Brougham Bridge, formulae that would work popped into his head. He was so overcome by excitement in his revelation that he impulsively vandalized the bridge by scratching the equations into the stonework (WTF?).
Hamiltons solution involved introducing 2 new imaginary-like constants:

You can multiply pairs of those constants in 6 different ways. Below, note that the commutative property of multiplication does not work here (order matters).
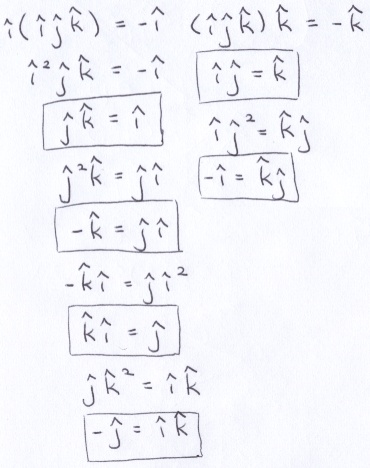
Using those pairs, its possible to multiply 2 quaternions together. When the real components are both 0 (absent), you end up with this:
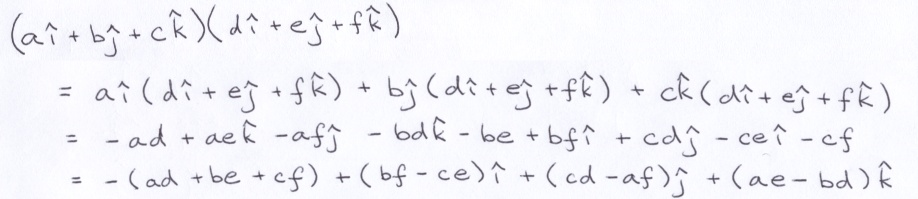
The real part on the left is the negative dot product and vector part on the right is the cross product. As mathematicians used quaternions in the decades after their discovery, they began to recognize that they were often using them to compute exactly those values. To make life easier, the vector product operators were introduced.
Dot product is an operation that takes place on the plane for which the vectors reside. The image below shows a view of that plane.

These vectors contain only direction information; you can think of their tails as touching the origin. Vector u defines a line and vector v casts a perpendicular shadow onto that line. The problem is find vector p.
You can redraw it as 2 right triangles that share a common side and height.
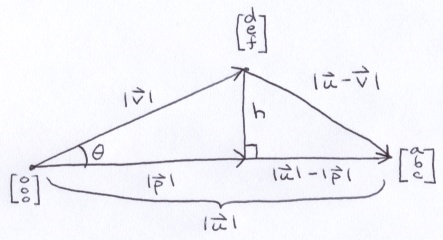
From there, its just a matter of applying the Pythagorean Theorem twice.

In addition to finding p, I wrote down a useful equation that shows that dot product is proportional to the magnitude of the vectors involved and the cosine of the angle between them. Note if the angle is 90 degrees, then the dot product is 0. If the angle is less-than 90, then the dot product is positive. And, if the angle is greater-than 90, then the dot product is negative.
But, what if vector u was a lot shorter than vector v?

As you can see, you end up with exactly the same answer. If the angle is greater than 90 degrees, you can negate one of the vectors to end up with something similar to one of the pictures above. Again, youll get the same answer.
Cross product is used to find a vector, w, perpendicular to the plane that u and v reside.
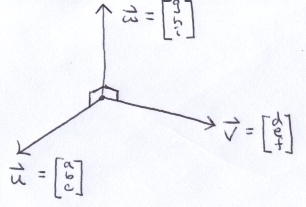
The angle between u and v is not necessarily 90, but the angles between u and w and v and w are both 90. From dot product, that gives us:
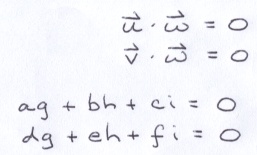
If u and v reside on a plane, as opposed to a line, then they cannot be parallel. But, if they were parallel, then they would only be distinguishable by some constant k.
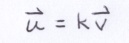
If they are not parallel, then at least one of the following relationships cannot exist.
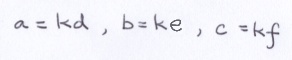
Suppose that the first or the second relationship is false. Then, we can rewrite the 2 original equations like this:
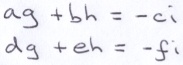
Next, we solve for g and h using Cramers Rule. Note that if the first and the second of the aforementioned relationships were both true, then we would be dividing by 0.

We end up with this:
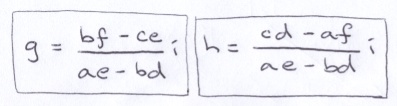
Now, you have some freedom here. You can actually set i to any value of your choosing and compute g and h accordingly. The resulting vector, w, will be perpendicular to the uv-plane. But, you may happen to notice that the (non-zero) denominators of both fractions in the formulae are the same. If you set i to that value, the denominators vanish and the result is the definition of cross product.
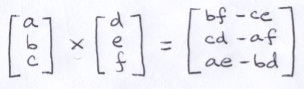
If the first and the second of the aforementioned relationships were true, then you could make a similar argument using the second and the third instead since at least one of them must be false assuming the vectors are not parallel. When they are parallel, the cross product is a null vector.
One important aspect of cross product (not proved here) is that it obeys the right-hand rule.
Finally, using all these vector ideas, I put together the following utility class.
public final class Vec {
|
Its unfortunate that Java does not support operator overloading. Instead, this is an all static class like the Math class.
The original Amiga Juggler animation was a 1 second loop consisting of 24 frames rendered at 320×200 resolution. I am aiming for 30 frames rendered at the HD resolution of 1920×1080. However, during testing, Ill render 1 frame at a third of that resolution (640×360). To that end, I need some boilerplate code to save an image.
import java.awt.image.*;
|

0 hours, 0 minutes, 0 seconds, 191 milliseconds
As you can see, it stores an all black image.
The main method contains code that outputs the rendering time (ray tracing is a slow process).
The pixels array will store the RGB values of each pixel in the image as it is rendered. Each color intensity component is in the range of 0.0 (darkest) to 1.0 (lightest). However, to compute the color value of a pixel, the code will statistically sample that part of the 3D scene a specified number of times (the constant SAMPLES) and it will average the samples together. The pixels array stores the sum of all the samples for each pixel. The saveImage method divides by the number of samples to convert the sum into an average.
For saving, the pixels array is temporarily converted into a BufferedImage. The BufferedImage.setRGB method expects an integer array where color intensities are in the range of 0 to 255. Unfortunately, we cannot simply multiply the pixels array values by 255 because the relationship between them is not linear. The actual brightness of a monitor pixel increases exponentially with the size of that integer value by a power of a constant called gamma (typically 2.2 on PCs and 1.8 on Macs). To compensate, the pixels array values are raised to the inverse of gamma before multiplying.
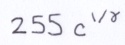
To push this machine to the max, I added code to render in parallel executing threads.
private int runningCount;
|
This is a Dell Studio XPS 435T with an Intel Core i7 CPU 920 at 2.67 GHz with 64-bit Vista. Runtime.getRuntime().availableProcessors() returns 8 and I confirmed that it takes 8 threads before the Task Manager reports 100% CPU usage.
Each thread will work on separate rows of the image. The getNextRowIndex method returns the next row of the image yet to be rendered.
I decided it would be nice to see the output as it is slowly generated. To make that happen, I created a panel capable of displaying images.
import java.awt.*;
|
Next, I created a frame to display the panel. The constructor captures a BufferedImage and calling the imageUpdated method forces it to repaint.
import java.awt.*;
|
To support the frame, I had to move some stuff around. There is no longer a global pixels array. Instead, the render method allocates an int array representing color intensities of a single row with RGB values compatible with BufferedImage. The render method does the conversion itself from double intensities to int intensities by dividing by the number of samples to compute the average, applying gamma correction and then multiplying by 255. When it finishes rendering a row, it invokes rowCompleted. That method updates the BufferedImage and it forces the RenderFrame to repaint.
import java.awt.image.*;
|
To test it out, the inner loop in the render method contains code to slowly set pixels red.

The virtual camera is based on the camera obscura and the pinhole camera. Surprisingly, a real camera does not actually need a lens to function. A pinhole-sized aperture ensures that each spot on the film is only exposed to light arriving from one particular direction. Unfortunately, in the real world, the smaller the aperture, the longer the exposure time.
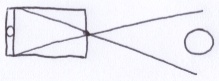
Instead of putting virtual film behind the pinhole, a virtual screen is placed in front of it. Geometrically, it works the same way. Rather than a pinhole, consider it as the pupil of a virtual eye staring at the center of the virtual screen.
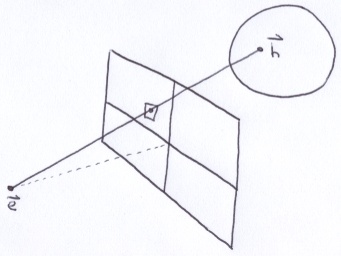
The ray tracer will follow the pathway of light backwards from the eye, through the virtual screen and out into the scene. In this way, the virtual screen acts like a window. Each pixel in the image has a corresponding point on the virtual screen in 3D space. Before it can cast a ray out into the scene, it has to figure out the direction of the ray.
I should mention that the coordinate system used looks like this:
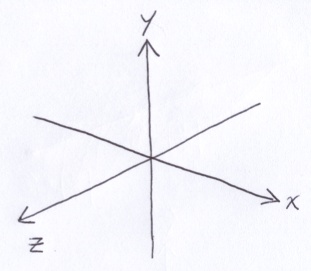
The position and the orientation of the virtual screen is determined by 3 things: the location of the eye, e; a point that the eye is looking at, l; and, the distance, D, between the eye and the center of the virtual screen, c.
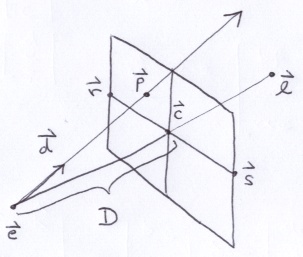
We need to construct an orthonormal basis (ONB) situated at the center of the screen, c.
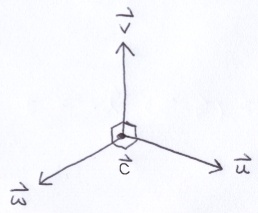
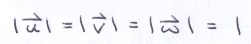
The unit vectors, u, v and w, are perpendicular to each other. Collectively, the point c and the ONB define a right-handed coordinate system. The point c acts like the origin. The vector u serves as the x-axis of the virtual screen. The vector v acts as the y-axis of the virtual screen. And, the vector w points toward the eye.
If you had some point p = (a, b, e) and you wanted to know where it was located in that coordinate system, you could position it using a variation of the ray equation.
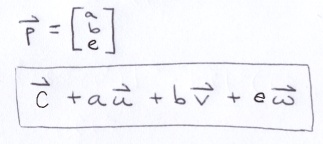
In our case, p represents a point on the virtual screen; so, e = 0.
For the general case, I added 2 new methods to the Vec utility class.
// p = o + p[0] u + p[1] v + p[2] w
|
The unit vector w is the easiest of the 3 to obtain:
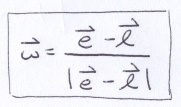
The formula inspired this addition to the Vec utility:
// v = ( head - tail ) / | head - tail |
|
There is already a subtract method to construct a non-unit vector from 2 point vectors.
Now that we have w, we can find c by starting at e and traveling a distance of −D along w using the ray equation (w points toward the e).
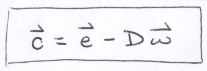
On the picture of the virtual screen above, observe points r and s. Imagine that the virtual screen were a camera that you were holding with your hands over r and s. You can rotate around (shoot the photo in any direction) and you can tilt the camera upwards and downwards. But, you would typically keep the line between r and s level. In this way, when you take the picture, the horizon will be parallel to the bottom of the photograph. Rarely do you roll the camera because it produces strange photographs.
Well construct the remainder of the ONB with the assumption that there is no roll. If you do need to roll the virtual camera, you can rotate u and v around w after the ONB is fully constructed. No camera roll is used in this project.
If there is no roll, then u is perpendicular to the normal of the ground plane that the juggler stands on, n = (0, 1, 0). And, by the definition of the ONB, u is also perpendicular to w. Hence, we can find u using:
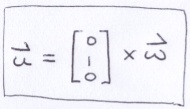
Again from the definition of the ONB, we can now solve for v.
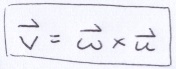
You can verify that applying cross products in this sequence does produce a right-handed coordinate system.
There is only 1 catch with the above construction: If w is parallel to the ground normal, n, then taking the cross product produces a null vector. Meaning, if you are looking straight up or straight down, then it will fail. But, its clear what u and v should be in those cases.
I added these methods to Vec:
public static final double TINY = 1e-9;
|
The input of the onb method is w and the output is u and v.
Putting it all together, I added this to the top of the render method:
double[] u = new double[3];
|
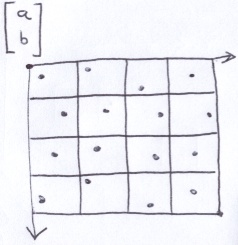
We normally think of addressing pixels in an image or on the screen in terms of row and column index. The upper-left corner is origin and the y-axis points downwards. Consider this 4×4 image:

The width and height are 4, but we use the indices 0 to 3 (inclusive). Instead of row and column indices, consider the upper-left corner of each pixel as the origin of that pixel. For instance, the upper-left corner of the lower-rightmost pixel is (3, 3). The lower-right corner of that pixel is (4, 4). In this way, it is possible to refer to points anywhere on the image, even within pixels.
Now, consider some arbitrary point on the image that we want to find the equivalent point in 3D space on the virtual screen. The image has a width and height of W and H respectively.
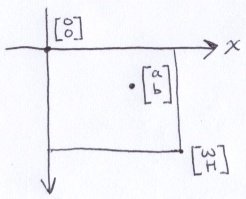
First, without modifying the image, Ill move the origin to the lower-left and Ill reverse the direction of the y-axis. To address the same point on the image, the coordinates need to change to:

Again, without modifying the image, Ill move the origin to the center of the image and adjust the points coordinates to compensate.
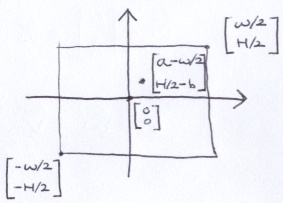
Now, lets assume that the virtual screen has the same aspect ratio as the image. Well specify the width of the virtual screen as a constant in the program. For this discussion, Ill refer to the virtual screen width as A and the virtual screen height as B.
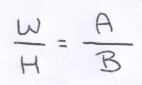
That gives us a way to find the virtual screen height:

If we had some arbitrary point (x, y) in the image aspect ratio and we needed to convert it to the virtual screen aspect ratio, we could accomplish the conversion with this:
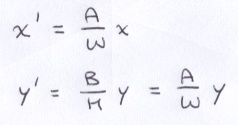
Combining the last 2 concepts leaves us with this:
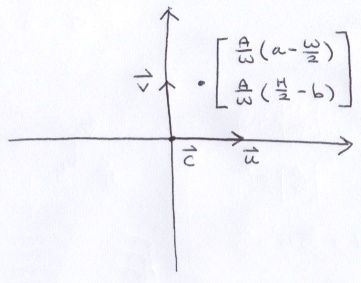
Finally, we have a way to transform some arbitrary 2D point (a, b) on the image to a 3D point on the virtual screen.
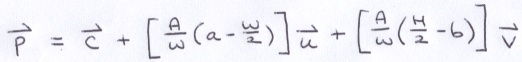
That formula inspired these additions to Vec:
// p = o + p[0] u + p[1] v
|
Since the point, p, on the virtual screen is known, we can finally compute the direction of the ray, d:
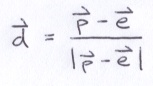
As mentioned above, the ray tracer will fire several rays through each pixel at slightly different coordinates to sample the 3D scene and then it will assign that pixel to the average of the results. To accomplish this, an image pixel is uniformly divided into a grid. Within each grid cell, a random point is chosen. This is known as jittered sampling. There are superior sampling techniques, but this technique works well enough and its easy to code. Below is an example of a sampled image pixel.
Generating pseudorandom values may be a computationally expensive operation. To guard against that possibility, I created a utility class that stores a large cache of random values.
public class RandomDoubles {
|
The cache is initialized when the first instance of RandomDoubles is created. 70001 is a prime number. I chose a prime to reduce the chances of strange patterns from showing up in the output image as a consequence of cyclically using the same set of random values.
Here is the render method after introducing random sampling:
private void render() {
|
The square-root of the number of samples, SQRT_SAMPLES, can be increased to improve image quality. Notice that when it is 1, instead of using a random sample, the sample is taken in the center of the pixel.
The juggling robot is constructed entirely out of spheres. The sky also appears to be a hemisphere. So, it is pertinent to work out how to intersect a ray and a sphere.
Below, a sphere of radius R is centered about p. A ray originating from o, fired in direction d, strikes the sphere at some point (x, y, z).

Now we have the amount of time it takes for the ray to reach a sphere from the virtual eye. We will apply this formula to every sphere in the scene. If the value within the square-root is negative, then the ray does not intersect the sphere. Of the ones that do intersect, the one with the minimal time is the one that we see. Well almost. If a sphere is behind the eye, this formula will output a negative time value. Intersection only took place if time is positive.
We actually need to constrain time a bit more. The eye is not the only point that we will be casting rays from. For example, when a ray bounces off one of the mirrored spheres, we will cast a new ray off its surface. To prevent the possibility of intersection between a ray and a surface that emitted the ray, we need to make sure that time is greater than a tiny positive value that well call epsilon. Also, we need to make sure that time is smaller than some max value. For example, to determine if a surface is illuminated, well cast a ray back to a light source. In that case, time cannot be greater than the time it takes to reach the light source. Any intersections that occur beyond the source of light cannot be considered.
Once we locate the intersection with minimal time, well compute the color of the hit point using Phong Shading. Phong Shading takes into account the following vectors:
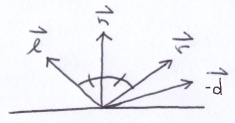
All of the vectors are unit vectors. The vector d is the direction of the incident ray. The negation of d points back to the rays origin, back to the virtual eye. The vector n is the surface normal. In case of a sphere, it is the vector between the hit point and the center of the sphere, normalized. However, it is possible that we may need to negate the normal to face the viewer. The angle between n and −d must be less-than-or-equal-to 90 degrees. Meaning, if n dot d is positive, then we reverse the normal. The sky is a good example of this. It is the interior surface of a hemisphere and the normal must point inwards. The vector l is a unit vector pointing toward a light source. And, finally, the vector r is the mirror reflection of the vector l. It represents light originating from the light source and bouncing off of the surface.
Since Phong Shading uses a mirror reflection vector, lets consider bouncing a ray off of one of the mirror spheres. Below, a ray traveling in direction d strikes a surface at point h with normal n and then it reflects in direction r.
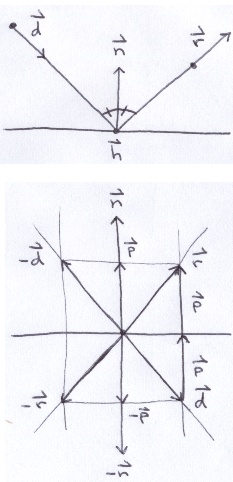
Vector p is the projection of −d onto n (vector projection was illustrated in step 1).
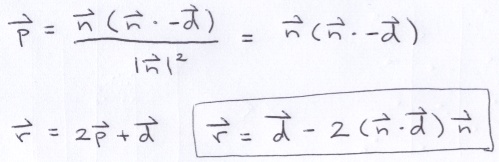
But, for Phong Shading, vector l actually points toward the light source; its in the opposite direction that the light ray travels. If we negate the ray direction, we end up with:
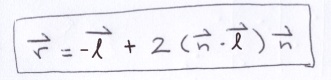
Note, if l dot n < 0 (greater than 90 degrees), then the light source is on the opposite side of the surface and none of its light reaches the side that we are viewing. Also, we need to cast a ray back to the light source to determine if there are any objects in the way. If the path to the light source is interrupted, then the surface is in shadow and only ambient light comes into play.
Finally, to shade the surface, we apply the Phong reflection model.
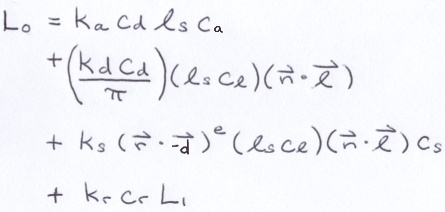
L represents radiance. We need to apply this formula 3 times, once for each RGB color intensity component. There is only one light source in this project. If there were multiple light sources, we would have to apply it to each of them and add them together.
There are 2 dot products in the formula. If one of them returns a negative value, change it to 0. Meaning, if the light source and the normal are on opposite sides, then the light does not contribute to the color of the surface. And, if the reflected light ray cannot be viewed seen, then it does not contribute to the color either.
The 4 terms represent ambient, diffuse, specular and reflected light. Each term is weighted by a k constant that is typically between 0 and 1. Collectively, the constants enable you to change the behavior of the surface.
I created a class to describe the material of a surface.
public class Material {
|
Next, I created a class to house different types of materials. Right now, there is only red plastic. Its a bright red material that has a white specular highlight.
public final class Materials {
|
For ray-object intersection, I created an object called Intersection that represents the result. It contains the hit time, the hit point, the surface normal and the surface material at the hit point.
public class Intersection {
|
3D objects in the scene are represented by the following interface:
public interface IObject {
|
The intersect method returns true if the ray intersects the 3D object. If the primaryRay parameter is set to true, then additional information about the intersection will be stored in the intersection parameter. The parameters o and d are the origin and direction of the ray respectively. The maxTime parameter is the intersection time upper-bound. The epsilon lower-bound constant is defined in Main. Finally, the temps parameter are temporary vectors that can be used during the intersection calculation. The render method passes in 16 of them.
Here is an implementation using the ray-sphere intersection formula from above. Notice that if primaryRay is not set to true, it does not bother to compute the hit point and the surface normal. When casting shadow rays and when casting ambient occlusion rays, we only care about the return value.
public class Sphere implements IObject {
|
Finally, I updated the render method using the Phong Shading model and I tested it with a scene containing a single sphere.
private volatile IObject[] scene
|
Here is the result with 256 samples per pixel:

0 hours, 0 minutes, 3 seconds, 552 milliseconds
If you study the code, youll notice that I did not plug in the reflection term of the Phong Shading model yet.
The ground is a checkerboard covered plane. Below is a plane containing point p with a surface normal of n. The point (x, y, z) is some other point on the plane. Note that the vector between that point and p is perpendicular to n.
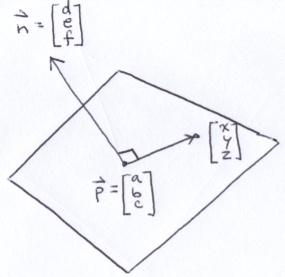
Since those vectors are perpendicular, we can take advantage of dot product to derive the equation for the plane.
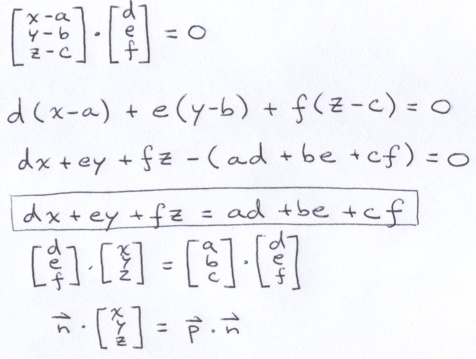
But, for this project, the ground is just the xz-plane. Meaning, p = (0, 0, 0) and n = (0, 1, 0). That leaves us with just y = 0. Nevertheless, we can still derive the generic equation for ray-plane intersection.

Our case is a little simpler:
Above, y = 0, simplifying it further.
Below is an aerial view of the xz-plane looking straight down the y-axis. The checkerboard consists of squares with side length s. For some point on a square, if we divide each coordinate by s and then floor it, we get a pair of integer coordinates of the upper-left corner of the square.
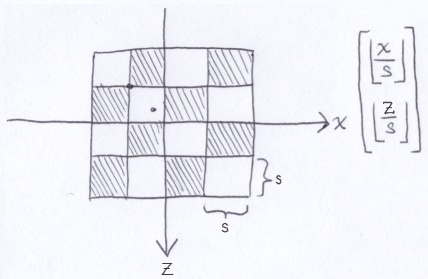
Notice that diagonals always have the same color. We can represent diagonals going from the lower-left to the upper-right by the following equation where t and a are integers.
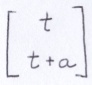
Above, a is the z-intercept. Adjusting it affects where the diagonal line crosses the z-axis. If we add the components together, we get:
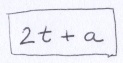
2t is an even number. Even plus even is even and even plus odd is odd. The parity (even/odd) of the sum is completely determined by a. This means we can determine the color of any point on the plane by dividing each coordinate component by s, flooring them and adding the resulting integer components together. The parity of the sum determines the color.
Based off the above discussion, I created the Ground:
public class Ground implements IObject {
|
I was worried that the sum of the floors might cause the long to overflow; so, I and-ed it with 1 to keep only the least-significant bit. The sum of those bits is all that matters in determining the parity of the sum.
I added 2 matte materials (materials without specular highlights and without reflections) to the Materials collection.
public static final Material GREEN_MATTE = new Material(
|
Finally, I created a scene containing the ground to test it out. Below is the result with 256 samples per pixel.

0 hours, 0 minutes, 3 seconds, 244 milliseconds
As mentioned above, the juggler lives under a giant dome also known as the sky.
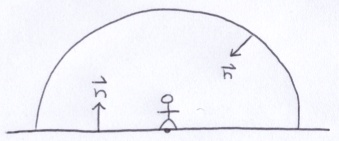
To generate the sky, I first updated the Materials class to make it easier to define materials.
public final class Materials {
|
Next, I defined this scene in Main:
private volatile IObject[] scene = {
|
Heres the result (256 samples per pixel):

0 hours, 0 minutes, 5 seconds, 959 milliseconds
I added a white matte material to Materials and then I defined a scene consisting of the ground, the sky and a sphere.
private volatile IObject[] scene = {
|
Here is the result:

The shadow on the ground is exactly the same color as the dark side of the sphere. Consequentially, there is no visual indication of where one ends and the other begins. This effect is the result of the Phong Shading model. It says if the light source cannot reach a surface, then the surface is colored based off ambient light resulting in a uniform dark color. Well enhance the image using ambient occlusion.
Ambient occlusion estimates the amount of ambient light reaching a surface by firing random rays off of the surface originating from the hit point. If the random ray strikes an object within some threshold distance, then there is no ambient light coming from that direction. The possible random rays exist within a hemisphere around the surface normal.
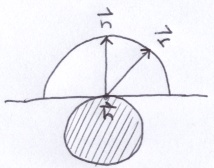
Similar to RandomDoubles, I created a class called RandomRays. It pre-calculates a large number of random unit vectors.
public class RandomRays {
|
To generate the random unit vectors in a uniform way, the inner loop creates a random vector within a within a cube bounded between (−1, −1, −1)–(1, 1, 1). A unit sphere fits snuggly within the cube.
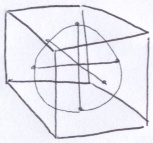
If the vector is outside of the unit sphere, it is thrown away. Otherwise, it is normalized, extending it to the surface of the unit sphere.
Next, the Material object was modified to include an ambientOcclusionPercent field. This is the percentage (0 to 1) of the ambient term for which well apply the occlusion test. If the hit point is fully occluded, well still give it a bit of ambient light equal to 1 minus that field.
public class Material {
|
The render method will not fire multiple occlusion rays off of the hit point. Instead, for each pixel sample, it will fire only 1. That means that the number of pixel samples needs to be large to enable many occlusion tests to average out. I added a boolean constant to Main turn on/off ambient occlusion. For test images, Ill shut it off when the number of samples is below some threshold.
The occlusion test ray needs to be within a hemisphere around the surface normal. This is accomplished by computing the dot product between the normal and the random occlusion ray. If the dot product is negative, then the occlusion ray is negated forcing the angle between the normal and the occlusion ray to be less-than 90.
if (hit) {
|
Below you can compare before and after (1024 samples per pixel).

0 hours, 0 minutes, 31 seconds, 340 milliseconds
The shadows currently have hard edges. This is because the light originates from a point-source. To alleviate that situation, well use a spherical light source.
I added a constant, LIGHT_RADIUS, to Main that specifies the radius of our single light source. I modified the render method to pick a random point on the sphere. That point will act as a point-light-source for the pixel sample. In the average, we will get the effect of a spherical light source. The random point needs to be on the hemisphere around the vector defined between the hit point and the light center point. Similar to what was done for ambient occlusion, if the dot product between that vector and the random vector is negative, the random vector is negated.
if (LIGHT_RADIUS > 0) {
|
Below you can see the result with 1024 samples per pixel. The hazy part of the shadow is called the penumbra.

0 hours, 0 minutes, 33 seconds, 868 milliseconds
Heres the same scene, but colorful materials are used:

In a typical ray tracer, reflection is generated by recursively applying the Phong Shading formula (see the fourth term in the sum). When a ray strikes a translucent material, it splits into a reflected ray and a transmitted ray. Recursion is used to follow those branching rays similar to traversing a tree data structure. However, in this project, there are no translucent materials, only reflective ones. The ray never splits. This means that a for-loop can be used to effectively expand the Phong Shading formula out for a specified number of iterations.
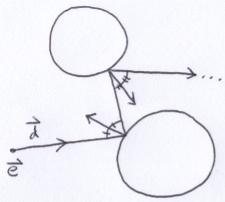
As a first step, I dropped Pi from the Phong Shading diffuse shading term. This simplifies specifying the constants when creating materials. Next, I added a method to Materials to make metals.
public static final Material YELLOW_METAL = createMetal(1, 1, 0);
|
Note that the diffuse, specular and reflective colors are all the same.
Next, I defined a color vector f within the render method to act as a filter. It is initialized to the radiance scaling factor (ls in the Phong Shading model) and I replaced the uses of the radiance scaling factor with the components of f. Meaning, each term of the Phong Shading model is scaled by f instead of ls.
I modified the render method to apply the Phong Shading formula up to MAX_DEPTH times.
Vec.assign(f, RADIANCE_SCALE, RADIANCE_SCALE, RADIANCE_SCALE);
|
At the very bottom of the loop, the code tests if the hit material is reflective. If not, it breaks out of the loop. If the material is reflective, the code reduces the values of the filter f in accordance with the Phong Shading model; it scales them down by the reflection weight and reflection color. If all 3 components of the filter drop below a specified threshold, then it breaks out of the loop because the filter would wipe out any effect of successive iterations. Finally, the direction vector is reflected around the surface normal using the formula discussed above.
if (bestIntersection.material.reflectionWeight > 0) {
|
This reflection loop is nested within the sampling loop. Meaning, the reflected rays contribute to the same pixel sample.
Here are the results with 256 samples per pixel. Note that the sphere does not reflect the sky because the reflection color, yellow, does not contain a blue component. However, yellow does contain a green component; hence, it is able to reflect both colors of the checkered ground.

0 hours, 0 minutes, 12 seconds, 573 milliseconds
To create a mirrored sphere, the ambient and the diffuse weights are set to 0. The reflective weight is set to 1 and the reflective color is set to white. The specular weight should also be set to 0, but I set it to 0.5 to create a specular highlight on the mirrored sphere. In the real world, a specular highlight is a blurry reflection of a light source. On a perfectly mirrored sphere, instead of a specular highlight, you would see a light bulb or the sun. In fact, the specular term of the Phong Shading model is essentially a hack. It can be replaced by modifying the reflective term to handle glossy reflections. A glossy reflection of a glowing object would appear as a specular highlight. But, for this project, I am not going to implement glossy reflections or glowing objects. Ill stick with the hack and just add a specular highlight to the mirrored sphere.
Below is a mirror sphere computed with 1024 samples per pixel.

0 hours, 0 minutes, 50 seconds, 14 milliseconds
Here is a red metallic sphere, a mirrored sphere and a yellow metallic sphere rendered at 256 samples per pixel. If you carefully compare the image below against the 2 previous images above, youll notice that there is something slightly wrong with the 2 previous images. Above, the reflective spheres do not reflect their own shadows. This is due to a bug that was fixed before generating the image below. Consider this document as a progress log. I am writing it in one pass as I develop the code and I failed to notice the problem when I attached the previous images.

0 hours, 0 minutes, 20 seconds, 15 milliseconds
Now, to answer the all important question, what happens if we put a few colored metallic spheres, a light source and the virtual camera within a mirrored sphere?

0 hours, 1 minute, 17 seconds, 142 milliseconds
To simulate motion blur, the scene must be updated between each pixel sample in accordance with the motion occurring in that animation frame. This animation will consist of 30 frames indexed from 0 to 29 (inclusive), but time will go from 0 to 30 time units where each time unit is 1/30th of a second. Some arbitrary frame, x, represents the time period x (inclusive) to x + 1 (exclusive). In the timeline below, the vertical lines are points in time. Below the timeline are the frame indices.
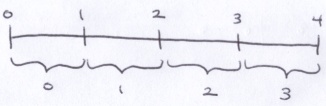
A unit of time needs to be sampled similarly to how a pixel is sampled. The time unit will be divided by the number of samples and within each division, a random sample will be selected.
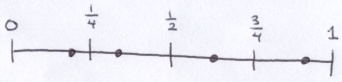
Each pixel sample will have an associated time sample from 0 (inclusive) to 1 (exclusive). However, pixel sampling is occurring within each pixel by scanning from left-to-right, top-to-bottom. I want to make sure that there is no correlation between the pixel sample and the time sample; that is, I do not want the upper-left corner of a pixel to always have a small time sample and the lower-right corner of a pixel to have a high time sample. To that end, I created a class called RandomTimes. After it divides up the unit time and selects random times within each division, it shuffles the order of the samples.
import java.util.*;
|
Since each thread will update the scene between casting rays, each thread needs its own copy of the scene. To generate it, I added a createScene method. To update the scene, I introduced an updateScene method that takes as parameters: the frame index, the time sample within the frame (0 to 1), and the scene to be updated. As a test, I created a scene containing the ground, the sky and a red metallic sphere. The updateScene method moves the red metallic sphere linearly based on the time sample.
private IObject[] createScene() {
|
The nested loops within render now looks like this:
while(true) {
|
Above, for each pixel, the code obtains a new set of time samples. Just before it enters the reflection loop, it updates the scene with a different time sample. The results look like this (256 samples/pixel):

0 hours, 0 minutes, 13 seconds, 401 milliseconds
Typically, when a person learns to juggle, the first thing he or she picks up is a figure-eight pattern known as the cascade. But, the Amiga Juggler tosses balls in a circular pattern called the shower. The pattern consists of 2 arcs. It tosses balls on a high arc from his left hand to his right hand. It returns the balls in a low arc directly below the high arc.
When a ball is tossed from hand-to-hand it follows a ballistic trajectory.
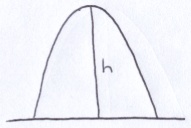
The x and the y components of the trajectory are independent. The ball moves linearly in the x-direction starting from an initial value of x0 and travels at a constant rate v0. In this way, the x component is governed by the ray equation. We know the amount of time it takes for the ball to traverse the arc and that provides a way to compute the velocity in the x-direction.
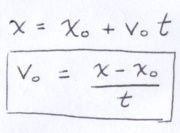
The maximum velocity in the y-direction, v, is a function of the height of the arc, h, and the acceleration due to gravity, g. Since all the potential energy stored in the ball at the apex is converted into kinetic energy when it reaches the bottom of the arc, we can express the relationship between v, h and g by equating the formulae for both types of energy.
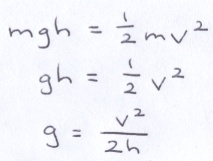
Movement in the y-direction is governed by the parabolic formula below where y0 is the initial height of the ball, v0 is the initial velocity in the y-direction, g is the acceleration due to gravity (a positive constant) and t is time.

Due to the symmetry of the arc, the starting and the ending heights are the same. Also, the magnitudes of the starting and ending velocities in the y-direction are the same, but opposite in sign.
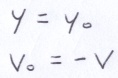
The derivation below shows that the height of the arc and the time it takes the ball to traverse the arc determines the maximum velocity of the ball in the negative y-direction. Also, from above, the acceleration due to gravity is computable from the maximum velocity and the arc height.
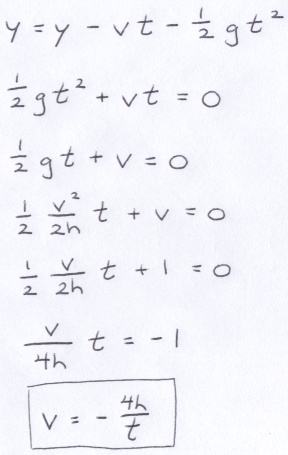
To test out these formulas, I modified the launch method to generate 30 animation frames.
public void launch() throws Throwable {
|
Next, I added a series of constants to control the arcs. Essentially, you can specify the coordinates of the hands and the height of the upper arc. The rest of the constants are derived from these values and the fact that it takes 30 frames to traverse the lower arc and 60 frames to traverse the upper arc.
public static final double JUGGLE_X0 = -75;
|
Then it was just a matter of modifying the createScene and updateScene methods to incorporate the parabolic arc formulae.
private IObject[] createScene() {
|
The program outputs 30 gifs at 320×180 resolution with 256 samples/pixel. I used UnFREEz to combine the images into an animated gif. Below, the background seems to flicker a bit because the animated gif format is crummy. That effect does not exist in the individual images.

0 hours, 1 minute, 14 seconds, 209 milliseconds
The arms and legs of the juggler consist of spheres packed into lines. As far as I can tell, the juggler stands with his right foot forward and his left foot back. As he juggles, the hips move up and down. In one animation frame, the left leg looks almost straight; where as the right knee is slightly bent.
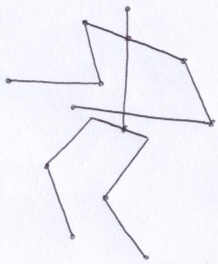
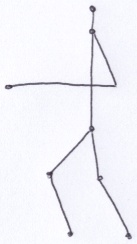
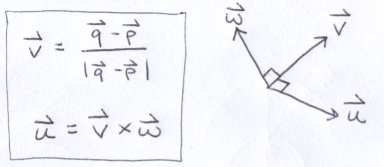
Each appendage consists of 2 line segments connected by a joint. To make appendages easy to control, I established the following model: The lengths of the line segments are A and B. The appendage exists in a plane with normal w. The end points of the appendage are p and q. The normalized difference between those points establishes a vector v. The cross product of v and w generates u, completing an orthonormal basis (ONB) for the appendage. I need to find the location of the joint, (x, y), which appears in the direction of positive u. The point (x, y) is in the coordinate system defined by the ONB where p is the origin and z = 0.
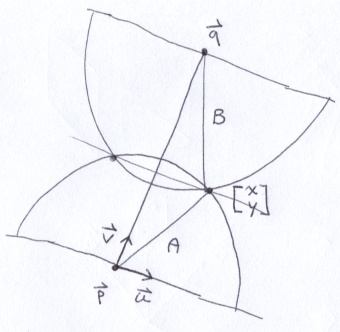
You can redraw the appendage as 2 right-triangles that share a common height.
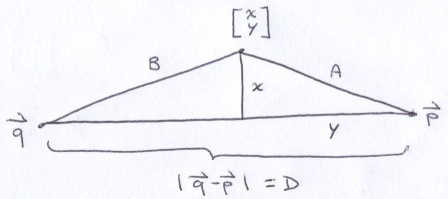
From there its just a matter of applying the Pythagorean Theorem twice and solving for x and y.
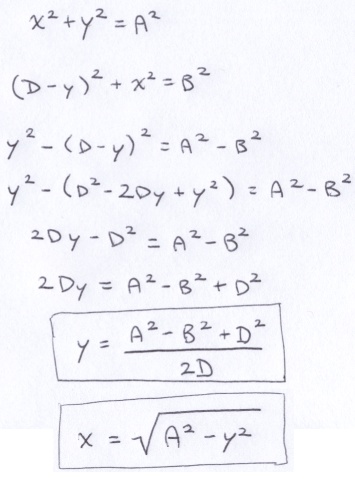
If the value within the square-root is negative, then it is not possible to construct an appendage with the specified parameters.
To test the concept, I created a scene containing an appendage. The appendage consists of 2 segments, each composed of 8 spheres, plus an extra sphere for the joint. In total, thats 17 spheres.
private IObject[] createScene() {
|
Below is a method I added to update an appendage based on the parameters discussed above. sceneIndex is the offset into scene where the appendage is stored. The parameters p, q, w, A and B control the appendage as described above. countA and countB are the number of spheres in each segment. Neither count includes the joint; the total number of spheres in the appendage is countA + 1 + countB. The spheres must be in the following order within scene: segment A spheres from p to j, the joint sphere at j, and segment B spheres from q to j. The temps parameter is a set of temporary vectors used for intermediate calculations.
private void updateAppendage(
|
Finally, I modified updateScene to move the appendage. The appendage exists within the xy-plane, parallel to the virtual screen. The code anchors point p and it moves point q in a circular motion.
private void updateScene(
|
Heres the result (320×180, 256 samples/pixel):

0 hours, 3 minutes, 36 seconds, 200 milliseconds
Here is a frame from the Amiga Juggler animation. I added black bars to the left and right to force the image into the aspect ratio that I am interested in and then I scaled it to the size of my other test images.

The horizon line is slightly above center, which means that the camera is tilted somewhat downwards.
To help me match the original animation, I modified the program to load and blend this frame with my own. I introduced the following method to load the image into a double[][][] array. Note that it applies gamma correction.
private void loadImage(String name) throws Throwable {
|
Blending occurs within the render method using a weighted average. Currently, its equally weighted.
pixel[i] = 0.5 * pixel[i] + 0.5 * blendPixels[y][x][i];
|
The launch method loads the image and then it attaches a key listener to the frame. By pressing the up or down arrow-keys, I can control the y-coordinate of the look point. This enabled me to find the camera tilt. Ill reuse this framework in successive steps to further match the original animation.
public void launch() throws Throwable {
|

It dawned on me while I was trying to work out the camera angle that the Amiga 1000 does not display square pixels. To compensate, I scaled the animation frame horizontally by 86%.

Here is my attempt at reproducing the same view. Its not a perfect match, but its close enough.

Using the shadows, the square tiles and the spheres in the original animation frame as a guide, I worked out key coordinates in space that will help me align everything else. Below is my attempt to orient the mirrored spheres. Now all I need is the juggler.

0 hours, 1 minute, 10 seconds, 138 milliseconds
Next, I sized and positioned the head, neck and torso spheres (64 samples/pixel).

0 hours, 0 minutes, 40 seconds, 529 milliseconds
Its unclear if the juggler in the original animation has a large, white button on his chest or if that is just a large specular highlight as seen in the above animation.
The torso definitely bobs up and down during juggling. I measured the range of the bob and I used cosine to simulate the effect. Below is the result with 64 samples/pixel.

0 hours, 0 minutes, 42 seconds, 385 milliseconds
The head also sways side-to-side. To achieve that, I constructed an orthonormal basis centered at the crotch point between the hips. In the image below, the unit vector v follows a circular path. Using v and the ray equation is sufficient to position the torso, the neck and the head. The unit vector u will be used with v for the shoulders, the hips and the appendages.
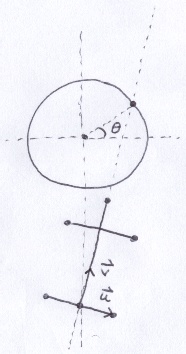
Here is the result with 64 samples per pixel.

0 hours, 0 minutes, 45 seconds, 459 milliseconds
Using the ONB created in the prior step, I attached the legs. Below you can see the result with 64 samples/pixel. The knees bend independently because one foot is forward and the other is back and because the hips are tilting from side-to-side. The thigh is 80% shorter than the calf.

0 hours, 2 minutes, 15 seconds, 349 milliseconds
Again using the crotch-centered coordinate system, I attached the arms to the shoulder points. The normal vector of each arm plane is based on the angle between the elbow point and the shoulder point. The hand points rotate around an arbitrary point in space such that the angle is based on cosine of time.
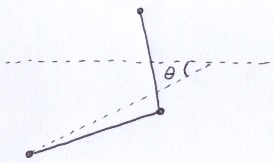
Below is the result with 16 samples/pixel.

0 hours, 0 minutes, 54 seconds, 850 milliseconds
To help me match colors sampled from frames of the original animation, I added 2 new methods to the Materials class.
public static double[] createColor(int hexColor, double scale) {
|
They accept a color in the form of an RGB hex value, the format readily available from photo-editing software. Gamma correction is applied to convert the color into the form necessary for the ray tracer. The second parameter provides a convenient way to scale the result.
In the original animation, the yellow and green squares closest to the viewer are pure, max yellow and green respectively. On the ground, within the jugglers shadow, the squares are reduced to 40% of their original color intensities. This means that the ambient weight in the Phong Shading Model is set to 0.4 for the ground material. For the spheres, it is closer to 0.15.
It was relatively easy to measure colors and to derive materials from them to color the ground and the spheres; however, the sky proved to be a bigger challenge. Close to the horizon the sky color is washed out with a high saturation, but high above, the sky is dark blue as revealed by the reflection in the mirrored spheres. Thats an effect that cannot be produced by diffuse and specular lighting with a single point light source.
To overcome the problem, I added a method called update to the Material class. The method is an empty stub.
public void update(double[] hitPoint) {
|
I modified the render method to call update with the ray-intersection hit point just prior to using the material in the Phong Shading Model. Then, I introduced a class that extends Material and overrides update to color the sky based on elevation.
public class SkyMaterial extends Material {
|
Notice that the sky material uses only ambient lighting, ignoring the other terms of the Phong Shading Model. The interpolate method used within update is essentially the ray equation. It performs linear interpolation between 2 specified points.
// a = b + (c - b) * s [s = 0 is b, s = 1 is c]
|
Here is the result with 256 samples per pixel.

0 hours, 1 minute, 41 seconds, 322 milliseconds
On a side note, in the original animation, I found a frame where one of the balls casts a shadow over the jugglers chest. The white button vanishes in the shadow, which demonstrates that it is indeed just a specular highlight.
Next, I worked out the position of the eyes and the hair.
Below is the result with 49 samples/pixel.

0 hours, 2 minutes, 26 seconds, 609 millisecondsHeres a frame rendered with 1024 samples/pixel.

Now, its time to render. But, before we do, lets take a look at the final versions of createScene and updateScene.
private IObject[] createScene() {
|
As you can see, the scene consists of 85 spheres and the ground plane. Any initial sphere positions specified in createScene are actually overridden by the formulae in updateScene. The createScene method only determines the sizes and the materials of the spheres.
I rendered the frames at 640×360 and at 1920×1080 with 1024 samples/pixel. At the larger (HD) resolution, it took approximately 1 hour to render each frame. Ironically, according to Eric Grahams documentation, each frame of the original animation also took about an hour to render on the Amiga 1000. But, the original animation was rendered at 320×200 and the renderer only used 1 sample/pixel. Thats 64,000 rays versus 2,123,366,400 rays for each image. Its also unlikely that it applied ambient occlusion or that it used double-precision floating-point operations. Being conservative, it would have taken about 114 years to generate the complete HD animation on the Amiga 1000. If you launched the program back in 1985 when the Amiga 1000 was introduced, on 5 of those machines, they would have collectively completed the job in 2008.
I merged the frames together using VirtualDub. At 30 frames/sec, there is only 1 second of animation. I wanted it to loop 30 times, but I could not get VirtualDub to import the images more than once. So, I simply wrote a program to duplicate the files and then I imported all 900.
package jugglerfilenames;
|
The original animation was accompanied by a clank sound every time the mirrored spheres contacted the robots arms. I decided to add some royalty free music reminiscent of the demoscene. I downloaded "Double O" by Kevin MacLeod (incompetech.com), I edited it with Audacity and then I imported it into VirtualDub.
VirtualDub produced an uncompressed AVI file. I used SUPER © to compress it into an MP4 before uploading it to YouTube.
Here is the final version of the source used to render the HD frames. Below are results.
3 hours, 19 minutes, 28 seconds, 616 milliseconds
29 hours, 55 minutes, 17 seconds, 544 milliseconds